对搜索引擎优化的认识(搜索引擎概念及工作原理)
 三石哥
2022-10-28 09:20:49
361
三石哥
2022-10-28 09:20:49
361
SEO新手入门系列,搜索引擎工作原理
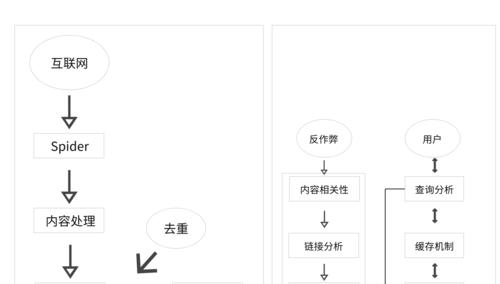
这一篇文章来详细的介绍下搜索引擎的工作原理,搜索引擎的工作顺序大致是:抓取网页(Crawing),建立索引(Indexing),排名显示(Ranking)。
就像在前一篇文章提到的,搜索引擎就是一个问答机器,他们去挖掘,理解,组织网上能发现的任何信息,然后把他们以相关的方式组织起来,再返回给使用者,为了能把你的网站展现给用户之前,最重要的一件事就是你的网站能够被搜索引擎发现 ,否则在SEPRs(搜索引擎结果页)是不会有你网站信息的。
搜索引擎是怎么工作的?
就如SEO小也开头说的,搜索引擎想把网站信息提供给用户,需要完成三个主要任务:
- 爬取网站(Crawing)会有很多蜘蛛程序,顺着URL一个网站一个网站的爬取网站内容。
- 创建索引(Indexing)对蜘蛛爬取的内容进行分类,创建相关索引,并储存在数据库中。
- 建立排名(Ranking)为可能的问题建立相关性排名,相关性最高的内容排在靠前的位置。
当然其中的技术实现是非常复杂的,作一名SEO新人,可能占时不需要深究这些问题,SEO小也在大学毕业的时候,作的毕业设计就是搜索引擎,当然那时候是使用第三方的索引分词库,我们大部分时间只要配置规则就可以,更深入的内容我会另写些篇文章来分享。
搜索引擎抓取(Crawing)
搜索引擎要想把相关内容展示给用户,第一步做的就是派出他的小弟——搜索引擎爬虫(蜘蛛),他们会不停的抓取互联网上新的内容,或者更新数据库中旧的内容,内容的形式多种多样,有可能是网页,PDF文件,MP3音频文件,什么形式都有,但是他们都是通过URL去找到这些内容的。
")
搜索引擎一开始会有一些种子URL,这些URL都是一些质量比较高的链接地址,而且蜘蛛们就会顺着这些地址不断的往下抓取,在这个过程中,新发现的链接又会被作为新一轮爬取任务的种子URL,直到没有新的链接可以爬取。
搜索引擎索引(Indexing)
建立索引是一个非常复杂的过程,这个过程涉及的内容比较多的是计算机方面的内容,有算法,有地理环境,有社会学研究等等因素,搜索引擎会根据很多参数去控制这些内容的分类,但是最重要的一点,就是这些内容的相关性,相关性越高,被分在同一个分类的可能性就越高,建立索引是为了后期能快速展现给用户作准备,也是为排名提供数据基础。
搜索引擎排名(Ranking)
用户在搜索引擎输入框输入他的关键词,搜索引擎会用惊人的效率在他庞大的索引数据库中找到相关的内容,并按内容的相关性和一些其它的参数来对内容进行排序,这个过程就是搜索引擎排名,靠前的内容,在搜索引擎看来就是和用户的问题相关性越高的回答。
如果我们不想让搜索引擎把一些内容展示给用户,这也是可以办到的,但是大多数情况下我们不会这么做,搜索引擎优化的目的就是为了让用户看到我们,并能让搜索引擎优先展示我们想给用户看的内容。
搜索引擎能找到你么?
就像前面说的,如果要让自己的网站出现在SERPs中,那前提就是让网站被搜索引擎蜘蛛爬取和索引,如果你已经有了网站,你可以使用site命令来查看自己网站被收录的情况,就拿SEO小也为例,在谷歌搜索框输入site:www.51yuwa.com
可以看到SEO小也已经有135个网页已经被谷歌收录,这个结果是经常会变动的,能看到一个大概的数据,并不是特别的精准,还有很多没有显示的网页,用一些关键词也是能搜索到。如果想看更精准的结果,可以使用Google Search Console在收录功能中查看,这就相当于我们百度的站长平台,但是SEO小也个人觉得比百度站长的作用要大的多,所以SEO小也一般只会看GSC的数据,很少去看百度站长平台的数据,以后也会专门写几篇文章来介绍。
如果你使用site命令找不到网站的收录,那有可能是下面几种原因:
- 网站是新站,搜索引擎还没有收录。
- 网站没有外部导入链接,可以到一些平台发一些外链。
- 网站目录结构太深,太复杂,让搜索引擎爬虫抓取的效率太低。
- 网站可能包含一些阻止搜索引擎爬虫的代码,如noindex,nofollow
- 网站可能被搜索引擎处罚,因为一些作弊或者垃圾广告等。
我们有时候把精力太多的放在如何让搜索引擎抓取内容,却忽略如何不让搜索引擎不要爬取一些内容,比如说一些重复的页面,一些搜索参数,还有比如说公司的联系方式,留言等,这些内容被收录意义并不大,而且还会让搜索引擎不知道具体哪个界面是你最想展示给用户的,所以这时候我们就要告诉搜索引擎,哪些资源他不要花时间去爬取,这就要robots.txt文件出场了,这篇SEO教程先到这。
三分钟科普 , 搜索引擎优化?和俺本地化有什么关系?
前言
如果大家去一些LSP (Language Service Provider) 的官网看一下,会发现它们往往都会在网站本地化业务下涵盖一个叫做“搜索引擎优化”的服务。
T君的本篇文章就将简单介绍一下搜索引擎优化 (SEO) 的概念,以及与本地化的关系,然后介绍SEO的实现方法。T君预计用2-3篇推送来介绍完SEO这个并不简单的话题。
本文主要出于科普目的,所有信息均系互联网信息搜集、汇总、筛选、编写,倘若有任何错误,敬请大家后台留言指出。谢谢大家的支持。
本地化的概念可以简单解释为“一个产品为了适应目标地区用户的使用习惯,而做出调整”。本地化的存在是为了服务于“产品利润最大化”这一目的。而一款国际化的产品,进行本地化过程中最重要的一点 (之一) 就是语言。
Common Sense Advisory (CSA)与莱博智 (Lionbridge)曾经做过一个市场调查,结果显示72.4%的消费者倾向于购买母语产品信息的商品。72.1%的消费者在购买商品时只浏览母语内容的网站。
本地化行业标准委员会(LISA)的一份研究也指出,公司每花费1美元进行内容本地化,就可以收回25美元。
上述两个研究有力地支撑了内容本地化的重要性,不过却忽略了一点:如何让自己精心本地化的产品被广大潜在用户群体发现?
在互联网时代下,消费者寻找信息的首选恐怕就是使用搜索引擎检索。而搜索引擎却并不一定将公司产品立马呈现在搜索结果的第一页。如果自家产品无法出现在第一页会怎样——换个角度,作为消费者我们有多少耐心和时间去翻页呢?
这时候就需要搜索引擎优化(search engine optimization, SEO)。这是通过提升非付费搜索引擎结果的排名来提高网站流量以及品牌曝光度的技术。
SEO不仅依靠搜索引擎原理来提升排名,更重要的是研究人们在网上搜索什么,人们在网上期望得到什么样的答案,人们使用什么样的关键词,人们希望获取什么样的服务内容。如果把这些内容都搞明白,公司便可以将自己的产品做得更贴合潜在用户群的搜索习惯——理想情况下用户会在首页看到你为他们提供的产品。
了解用户的同时,还需要了解机器。搜索引擎的工作原理就像一个黑箱——我们一直使用它,却不知道它的原理。这次,T君尽可能用简单的文字解释清楚。
1 搜索引擎原理简述
搜索引擎的工作原理可以大致分为三个部分:
1.爬取 (crawling):检索互联网上的内容,找到内容对应的代码/URL。
2.索引 (indexing):有序地存储爬取过程中找到的内容;如果页面在索引中,就会作为相关搜索结果显示出来。
3.排名 (ranking):按照相关度由高到低排列检索结果。
爬取过程中,搜索引擎会通过一组程序(称为“爬虫”或“蜘蛛”)在互联网上发现/更新内容。所谓的内容,可以指网页、图片、视频、网页附件——所有这些内容都有一个“身份证号”,叫做统一资源定位符(Uniform Resource Locator, URL)。爬虫找到网页内容与对应的URL并存储,再根据网页内容中的其它URL跳转至别的内容,一步步操作下来就像是结了一张网,连接了网络当中的海量资源。
搜索引擎存储的内容就像一本词典,而索引就是拼音或者偏旁查字法。爬取的内容需要经过分析,存入索引数据库中。数据库内的网页文字内容都进行专门分析。
当用户进行搜索时,搜索引擎会检索索引数据库中高度相关的内容,然后对其进行排序。这种根据相关性对搜索结果进行排序的方法就是排名。一般可以认为网站排名越高,搜索引擎就越相信网站与查询的相关性越高。
1.1 告诉搜索引擎:“你过来啊”
有时候公司不想让一些网页出现在搜索引擎中,例如网页内广告、过期内容、隐私内容等。网站开发者可以通过一些方法 (如robots.txt) 告知爬虫不要爬取此类网页的内容。当然,宣传产品的时候公司肯定希望产品介绍网页能够被搜索引擎检索到。因此,若想让内容被搜索引擎发现,首先确保它可以被爬虫程序访问并且是可索引的。否则,它就像隐形一样。
以谷歌为例,使用高级检索方法“site:51yuwa.com”就可以返回某个站点在谷歌索引中的所有结果。通过谷歌搜索控制台 (Google Search Console)还可以实现更精确的索引结果查询与监控。这其实就是搜索引擎优化的第一步:检验自己的网页是否被索引,哪些被索引,重要的页面是否被索引了。
爬取预算
爬取预算(crawl budget) 可理解为搜索引擎爬虫在离开某一站点前爬取的平均URL数量。合理的爬取预算能够让爬虫抓取更重要的页面,避免在无用的信息/页面上浪费时间。同时这也意味着用户检索时内容相关度能够更加集中。
用户最终还是需要在搭建网站时,通过HTML代码,给搜索引擎指示如何对待你的网页。这种指示叫做元指令(meta directives) 或元标签(meta tags)。它们一般存在于HTML页面的<head>标签中。感兴趣的读者可以自行了解。
1.2 搜索引擎:排排坐 吃果果
搜索引擎根据内容相关度对结果进行排名的技术是基于复杂的算法实现的。谷歌几乎每周,甚至每隔几天就会更新排名算法。如今机器学习、自然语言处理也都帮助搜索引擎更好地实现排名。
RankBrain是Google搜索引擎核心算法的机器学习组件。机器学习也是一种技术,它通过大量数据不断改进预测。换句话说,它总是在学习。因为它总是在学习,所以搜索排名结果会不断进步。
用户与搜索结果的交互行为也会影响搜索引擎的改进。一般有以下四个因素:
-
点击率(用户看到某搜索结果并点击进入该结果的百分比)
-
页面停留时间(用户点击进入到离开这个搜索结果的时间)
-
跳出率(点击某搜索结果且只看1个页面的用户所占百分比)
*跳出率的高低并不能直接反应搜索结果的质量优劣。用户有可能仅在这一个网页下就达成了自己的目的,也有可能看了一番没有达成目的而转而继续搜索。好比我们去美妆店只逛了一个品牌专柜就走了——我们既有可能仅在这一个专柜就买到了心仪商品,也有可能没买东西转而去其它专柜。
-
Pogo-sticking(指用户点击某搜索结果后快速返回页面并浏览其它结果的这一行为)
这四项指标构成了用户粘性指标(engagement metrics)。
不同的搜索引擎需要各自进行SEO
不同的搜索引擎,其排名算法各不相同。国际产品的本地化,理论上需要针对不同的搜索引擎分别执行SEO策略,但是国际范围内谷歌占据绝大多数市场份额,在预算有限的情况下,产品优先针对谷歌进行SEO。不过放眼中国内地,SEO就需要瞄准百度了。
读到这里,一个公司就可以做到让自己的网站被搜索引擎捕捉到,并通过一些办法检测网站的流量了。接下来T君要介绍的便是,如何通过合理编排网站内容,使得用户在使用关键词检索时,网站能够精确地被搜索引擎捕捉到,并呈现出用户满意的内容。
2 关键词调研
在搜索引擎输入框中输入关键词,按下回车,成千上万的结果就会呈现出来,而我们往往只会浏览前一两页的结果。
关键词调研有助于在产品本地化过程中,增进对目标市场的了解,以及了解客户如何搜索内容、服务、产品。一般关键词调研主要为了回答以下三个问题:
-
人们搜索什么?
-
多少人搜索它?
-
人们希望的信息是如何呈现的?
在进行关键词调研以优化搜索结果前,首先要知道,我们的产品是做什么的?我们的顾客是什么样的?我们的目标是什么(高点击率?高销量?高下载量?)?
例如,美国西雅图一家主打素食无麸质的“健康”冰激凌连锁店计划进行SEO,需要考虑什么要点呢?
人们在找什么样的冰淇淋、甜点、小吃?
谁在搜索这些产品?
-
青少年?学生?职场人士?中年人?
人们什么时候在找冰淇淋、零食、甜点等?
-
全年的搜索量会出现季节性趋势吗?
人们是如何寻找冰淇淋的?
-
他们用什么关键词?
-
他们会问什么问题?
-
在移动设备上执行的搜索是否更多?
为什么人们都在找冰淇淋?
-
人们是在特别寻找健康概念冰淇淋,还是只是想满足吃甜食的想法呢?
潜在的客户在哪里——本地?全国?全球?
尽管产品制造商有一万种方法将自己的产品吹到天花乱坠,但是顾客究竟如何搜索,才是最关键的。有专门分析关键词搜索的工具,输入一个关键词之后会给出若干相近的关键词/词组,并呈现它们的月均搜索量变化图。
2.1 关键词,长尾理论,季节与地域
关键词的数量与月均搜索频率符合长尾理论的关系。20%的关键词能够达到每月100k甚至更高的搜索频率,而剩下的80%的关键词 (它们就是long tail) 月均检索量可能低于10k。因而集中于几个关键词进行内容优化是一个合理的选择。
与此同时,大厂已经早早地占据了最最高频关键词,作为一个小企业/初创公司,退而求其次选择一个稍微低频的关键词/词组会收获更好的效果。例如一家小规模冰激凌店完全有理由放弃ice cream这样的高频词,转而投入organic milk and fruit ice cream这样更加具体的关键词以进行优化。
季节、地域也有可能影响到关键词调研。例如“送给女友的圣诞节礼物”检索量势必会在10-12月大幅上升,提前规划好届时需要更新的网站内容能够让商家抢得先机。谷歌拥有的关键词分析工具Google Keyword Planner则可以精细至城市、省级行政区、国家层面,让开发者进行关键词调研。例如半挂车在美国德克萨斯州更常称为“big rig”,而在纽约就会叫做”tractor trailer”,这显示出用语习惯对于SEO策略的影响。
2.2 消费者的目的
谷歌将用户的搜索行为概括为大致四种,它们对应了用户的各种检索目的,分别是:
-
了解(know):搜索信息
-
做(do):完成目标
-
网站(website):找到特定网站
-
线下(visit-in-person):找到线下实体店
而用户将自己的目的落脚到输入框中的检索格式时,谷歌又概括了以下五种:
-
信息询问(Informational queries):用户需要了解信息,例如查询历史人物生卒或者北京市常驻人口数量。
-
导航询问(Navigational queries):用户想要前往某一具体的网站,例如油管或NBA官网。
-
事务询问(Transactional queries):用户想要完成某个事务,例如购买机票或者线上听歌
-
商品调查(Commercial investigation):用户想要比较产品并找到最适合他们特定需求的产品,例如比较PS4与PS5。
-
本地询问(Local queries):用户想要找到当地的某些东西,例如小区附近的邮局,某地的三甲医院。
可以根据上述若干分类绘制出更精细的用户意图,进而布局SEO的策略。自搜索引擎诞生至今,搜索行为已经被地球上所有互联网用户执行了数万亿次,谷歌可以凭借这些数据几乎完美地提供搜索结果,而商户也能够利用这些数据进行“完美”的SEO。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
转载请注明来自专注SEO技术,教程,推广 - 8848SEO,本文标题:《对搜索引擎优化的认识(搜索引擎概念及工作原理)》




- 搜索
- 最新文章
- 热门文章
-
- 抖音代运营如何精准获客快速提升排名?
- 谷歌云Next大会对软件板块和ETF(5152)的影响是什么?
- Web开发的未来职业前景如何?
- 网站Title标题优化技巧有哪些?优化时应注意哪些事项?
- UI设计师必备技能有哪些?如何提升这些技能?
- 标题的seo的方法有哪些?如何优化标题提高搜索引擎排名?
- 如何实现银发经济自媒体运营的精准引爆?
- 服务器连接失败原因揭秘?如何快速解决无法连接问题?
- 矩阵账号搭建从申请到内容分发的实操步骤是什么?
- 2025年有哪些网页设计趋势不容错过?
- 如何通过代运营提升店铺销量?
- 2025年4月15日随笔档案,记录了哪些重要事件?
- ftp网站空间是什么?如何选择合适的ftp空间?
- 浏览器无法打开HTML页面?可能的原因和解决步骤是什么?
- 什么是数字营销及其重要性?
- 企业如何制定知识产权保护策略?保护策略集有哪些?
- 优秀网站设计的关键要素有哪些?
- 网站优化水平如何准确编写建议?有哪些技巧?
- 网站的死链接有什么影响?如何检测和修复死链接?
- uniapp前端框架是什么?它的特点和用途是什么?
- 热门tag
