你所不知道的Spider,它是如何工作的(你所不知道的Spider)
 游客
2024-04-22 12:15:02
125
游客
2024-04-22 12:15:02
125
搜索引擎Spider的工作原理:揭开搜索引擎背后的秘密
")
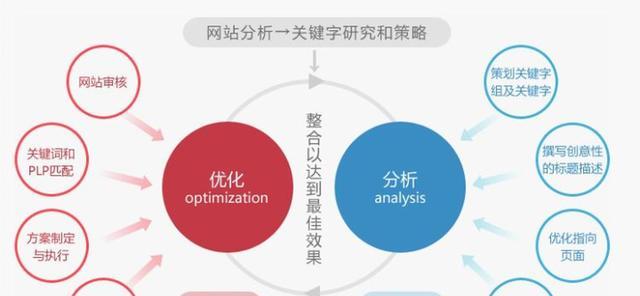
这其中隐藏着一个不为人所知的过程——Spider的工作,当我们输入关键词在搜索引擎中进行检索时,搜索引擎会快速地呈现出符合要求的网页。揭开Spider的工作原理、本文将带你深入探究搜索引擎背后的秘密。
Spider的定义与功能
存储到搜索引擎数据库中、Spider是搜索引擎中的一个重要组成部分、它的主要功能是自动访问互联网上的网页,内容等信息通过算法加工和处理,并将其中的链接。
Spider的工作流程
1.获取种子URL
作为爬行的起点、Spider首先从搜索引擎库中获取一些种子URL。
2.根据URL进行爬取
")
接下来,并提取出其中的链接信息,Spider会对这些种子URL进行爬取,再根据这些链接信息继续爬取。
3.识别和去除重复页面
避免出现重复页面、在爬取过程中,Spider还会进行页面去重操作。并减少数据库存储空间的浪费,这样做可以提高爬取效率。
4.解析和抓取页面信息
摘要,它会解析页面的HTML代码、关键词等,当Spider爬取到一个页面后、包括页面标题,并抓取其中的信息。
5.将信息存储到数据库中
并存储到搜索引擎的数据库中,Spider会将抓取到的信息通过算法处理。
Spider的运行策略
1.深度优先策略
这种策略可以保证尽可能多的网页被收录进搜索引擎库中、Spider采用深度优先策略进行页面的爬取。
2.时间限制策略
搜索引擎会对Spider的运行时间进行限制,为了保证Spider的运行效率,一般情况下不超过30分钟。影响其他用户的使用,这样可以避免Spider长时间占用服务器资源。
3.爬虫频率策略
以防止Spider过度访问某个网站而导致被禁止访问、搜索引擎还会对Spider的爬虫频率进行限制。
Spider的算法和技术
1.链接分析算法
并根据这些联系进行页面的爬取和链接提取,Spider通过链接分析算法来确定网页之间的联系。
2.机器学习技术
搜索引擎利用机器学习技术来优化Spider的运行效率和搜索结果的准确性。
3.自然语言处理技术
搜索引擎使用自然语言处理技术来提取关键词和摘要信息,从而提高搜索结果的质量,在页面信息的抓取和处理中。
Spider的应用与发展
1.智能搜索
个性化的搜索服务、将推出更加智能,搜索引擎正在向智能化方向发展,随着人工智能技术的发展。
2.移动化搜索
许多搜索引擎开始推出适应移动设备的搜索服务,移动化搜索已成为搜索引擎发展的重要方向。
3.语音搜索
对于特定人群而言具有很大的实用性、可以让用户通过语音输入关键词进行检索,语音搜索是一种新兴的搜索方式。
功能、运行策略以及算法和技术等方面深入探究了搜索引擎背后的秘密,工作流程、揭示了Spider的工作原理、本文从Spider的定义。为用户提供更加智能,便捷的搜索体验、搜索引擎将继续发展、在未来。
搜索引擎Spider的工作运行原理
总能够得到我们想要的答案、在我们使用搜索引擎的时候。有没有想过这背后的运行原理、但是?搜索引擎背后有一个叫做Spider的程序在默默运转,其实。本文将为大家揭秘搜索引擎Spider的工作运行原理。
Spider是什么?
中文翻译为蜘蛛,Spider,负责抓取互联网上的所有网页,它是搜索引擎的一部分。从一个页面到另一个页面,可以从一个网站到另一个网站,不断地收集信息,它是一种自动化程序。
Spider的作用是什么?
并建立索引、Spider的作用是将互联网上所有的网页抓取下来。每个页面都有一个索引指向它、索引就是一个网站的目录。搜索引擎会根据索引来找到相关的页面,当用户输入关键字进行搜索时。
")
Spider的工作过程是怎样的?
Spider首先从搜索引擎的数据库中获取待抓取的网址。并抓取网页上的信息、它按照一定的规则、依次访问这些网址。Spider会将其中的链接再加入到待抓取的队列中、当抓取到一个网页时。
Spider如何确定哪些页面需要被抓取?
Spider会根据搜索引擎的算法来判断哪些页面应该被抓取。它会优先抓取高质量、并忽略一些低质量、不安全的网站,高权威度的网站,一般来说。
Spider如何抓取网页上的信息?
抓取网页上的信息,Spider会按照一定的规则。图片,链接等信息,它会解析HTML代码、提取出其中的文字,并将其存储在搜索引擎的数据库中。
Spider如何处理JavaScript代码?
这会给Spider带来很大的困难,有些网站使用JavaScript代码来动态生成页面内容。Spider会使用一种叫做,为了解决这个问题“JavaScript引擎”以便能够正确地抓取页面上的信息,的程序来模拟浏览器行为。
Spider会不会抓取重复的网页?
Spider会在抓取之前先检查该页面是否已经被抓取过,为了避免重复抓取相同的网页。则不再重复抓取、如果已经被抓取过。提高效率,这样可以节省搜索引擎的资源。
Spider会不会遇到反爬虫机制?
会设置反爬虫机制、有些网站为了防止被爬虫抓取。使得搜索引擎无法正确地建立索引,这种机制可能会阻止Spider的抓取。Spider会使用一些技术手段来规避反爬虫机制,为了应对这个问题。
Spider会不会抓取敏感信息?
Spider会遵循一定的规则来处理敏感信息,为了保护用户的隐私。银行账号、密码等敏感信息的网页,它不会抓取包含用户个人信息。
Spider的抓取频率是多少?
Spider的抓取频率是根据搜索引擎的算法来确定的。不安全的网站则会被降低抓取频率或者被忽略掉,高权威度的网站会有更高的抓取频率,一般来说,高质量,而低质量。
Spider如何保证数据的准确性?
以保证最终建立索引的数据具有一定的质量和准确性,Spider会对抓取到的数据进行去重,为了保证数据的准确性、清洗,筛选等处理。
Spider的抓取深度是多少?
Spider的抓取深度是根据搜索引擎的算法来决定的。不安全的网站则会被限制抓取深度、高权威度的网站会有更深的抓取深度、高质量、一般来说,而低质量。
Spider的抓取速度是多少?
Spider的抓取速度是根据搜索引擎的算法来调整的。不安全的网站则会被限制抓取速度,而低质量,一般来说、高权威度的网站会有更快的抓取速度,高质量。
Spider对于SEO优化有什么影响?
Spider对于SEO优化非常重要。而Spider负责建立索引,SEO优化可以帮助网站提高搜索排名、直接影响搜索排名。以便被Spider正确地抓取和收录,SEO优化需要遵循搜索引擎的算法和规则。
是搜索引擎能够顺利运作的重要组成部分,搜索引擎背后的蜘蛛程序Spider。相信大家对于Spider的工作运行原理有了更深入的了解,通过本文的介绍。我们应该感谢这个默默无闻的“蜘蛛”让我们能够轻松地获取到互联网上的信息,。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
转载请注明来自专注SEO技术,教程,推广 - 8848SEO,本文标题:《你所不知道的Spider,它是如何工作的(你所不知道的Spider)》
标签:搜索引擎



- 搜索
- 最新文章
- 热门文章
-
- 2025年外贸建站平台有哪些主流工具?它们的优缺点是什么?
- Java程序员如何转型AI开发?需要哪些技能?
- AI数据标注应该如何学习?有哪些高效学习方法?
- 微信支付限额解除方法和操作流程是什么?
- 小米手机屏幕失灵修复和官方售后预约流程是什么?
- 抖音代运营如何精准获客快速提升排名?
- 想要运营好一个网站?如何制定有效的SEO策略?
- Web开发的未来职业前景如何?
- 谷歌云Next大会对软件板块和ETF(5152)的影响是什么?
- 淘宝账号被封处理和申诉恢复流程是什么?
- 有效的网站推广策略有哪些?
- 网站Title标题优化技巧有哪些?优化时应注意哪些事项?
- UI设计师必备技能有哪些?如何提升这些技能?
- seo搜索排名优化有哪些方法?如何提高网站的搜索排名?
- 图片SEO优化应该如何做?掌握这些技巧提升搜索引擎排名?
- GoogleCloud和AT&T联手提供5G边缘计算解决方案?对企业有何好处?
- 抖音“验证助手”升级如何查询官方客服联系记录?
- 如何实现银发经济自媒体运营的精准引爆?
- 标题的seo的方法有哪些?如何优化标题提高搜索引擎排名?
- 网站搜索排名优化怎么做?提升SEO效果的策略有哪些?
- 热门tag
